Before we begin we need to download and install the NLTK library for Python
pip install nltk>>> import nltkNow lets download the packages and tools we will need
>>> ntlk.download()Next we will want to import the books we will be using to learn NLTK with Python
>>> from nltk.book import*
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908Next we can look for the occurences of words. In NLP this is called concordance, and this allows us to search for the occurence of the word that we want to look at. Below we can see that there are 39 matches for the word grail in the corpus or text we are looking at.
>>> text6.concordance("grail")
Displaying 25 of 39 matches:
els sing ] Arthur , this is the Holy Grail . Look well , Arthur , for it is you
it is your sacred task to seek this grail . That is your purpose , Arthur ...
, Arthur ... the quest for the Holy Grail . [ boom ] [ singing stops ] LAUNCEL
an join us in our quest for the Holy Grail . FRENCH GUARD : Well , I ' ll ask h
ARTHUR : If you will not show us the Grail , we shall take your castle by force
s required if the quest for the Holy Grail were to be brought to a successful c
should separate , and search for the Grail individually . [ clop clop clop ] No
AD : You are the keepers of the Holy Grail ? ZOOT : The what ? GALAHAD : The Gr
il ? ZOOT : The what ? GALAHAD : The Grail . It is here . ZOOT : Oh , but you a
ease ! In God ' s name , show me the Grail ! ZOOT : Oh , you have suffered much
rment me no longer . I have seen the Grail ! PIGLET : There ' s no grail here .
en the Grail ! PIGLET : There ' s no grail here . GALAHAD : I have seen it ! I
are you going ? GALAHAD : I seek the Grail ! I have seen it , here in this cast
which , I have just remembered , is grail - shaped . It ' s not the first time
blem . GALAHAD : It ' s not the real Grail ? DINGO : Oh , wicked , bad , naught
ne punishment for setting alight the grail - shaped beacon . You must tie her d
: No , we ' ve got to find the Holy Grail . Come on ! GALAHAD : Oh , let me ha
, but they were still no nearer the Grail . Meanwhile , King Arthur and Sir Be
of whom you speak , he has seen the Grail ? OLD MAN : ... Ha ha ha ha ! Heh ,
o man has entered . ARTHUR : And the Grail . The Grail is there ? OLD MAN : The
tered . ARTHUR : And the Grail . The Grail is there ? OLD MAN : There is much d
has ever crossed . ARTHUR : But the Grail ! Where is the Grail ?! OLD MAN : Se
RTHUR : But the Grail ! Where is the Grail ?! OLD MAN : Seek you the Bridge of
Bridge of Death , which leads to the Grail ? OLD MAN : Heh , hee hee hee hee !
e the sign that leads us to the Holy Grail ! Brave , brave Concorde , you shallNext we can look at how certain words are used and which ones are similar in the text we are focusing on.
>>> text2.similar("monstrous")
very so exceedingly heartily a as good great extremely remarkably
sweet vast amazinglyDifferent authors utilize words in different contexts. The above code look at the use by Jane Austen. Let's go back and see how Mehlville utilized the same word.
>>> text1.similar("monstrous")
true contemptible christian abundant few part mean careful puzzled
mystifying passing curious loving wise doleful gamesome singular
delightfully perilous fearlessWe can see that Mehlville and Austen utilize the word differently in their books to convey different meanings and context.
We can also look at how 2 or more words share context with each other. We can use the text2.common_contexts([]) function to do so.
>>> text2.common_contexts(["monstrous", "very"])
a_pretty is_pretty am_glad be_glad a_lucky>>> text6.common_contexts(["grail"])
holy_. this_. the_, holy_were the_individually holy_? the_. the_!
no_here is_- real_? the_- the_? the_is the_?! holy_! a_?! holy_in
holy_could holy_returnsAs you can see we were able to find common contexts or phrases utilized with the above words. What happend if we have no words that have a common_contexts?
>>> text1.common_contexts(["monstrous","very"])
No common contexts were foundDepending on the text and the words we input we may not find anything. This reminds us that it is a good idea to know our subject matter.
Lexical Dispersion Plots:
You will need the plotlib library installed to utilize this
What is a lexical dispersion plot? This allows us to see where in the text a word occurs. This visualization makes it easy for us to look at the use of a word over the time (plot) of the text we are analyzing.
In the dispersion plot below we looked at the occurences of the words: behold, before, begat, justice, God, angel, Jesus, gabriel, and lord.
>>> text3.dispersion_plot(["behold","before","begat","justice","God","angel","Jesus","gabriel","lord"])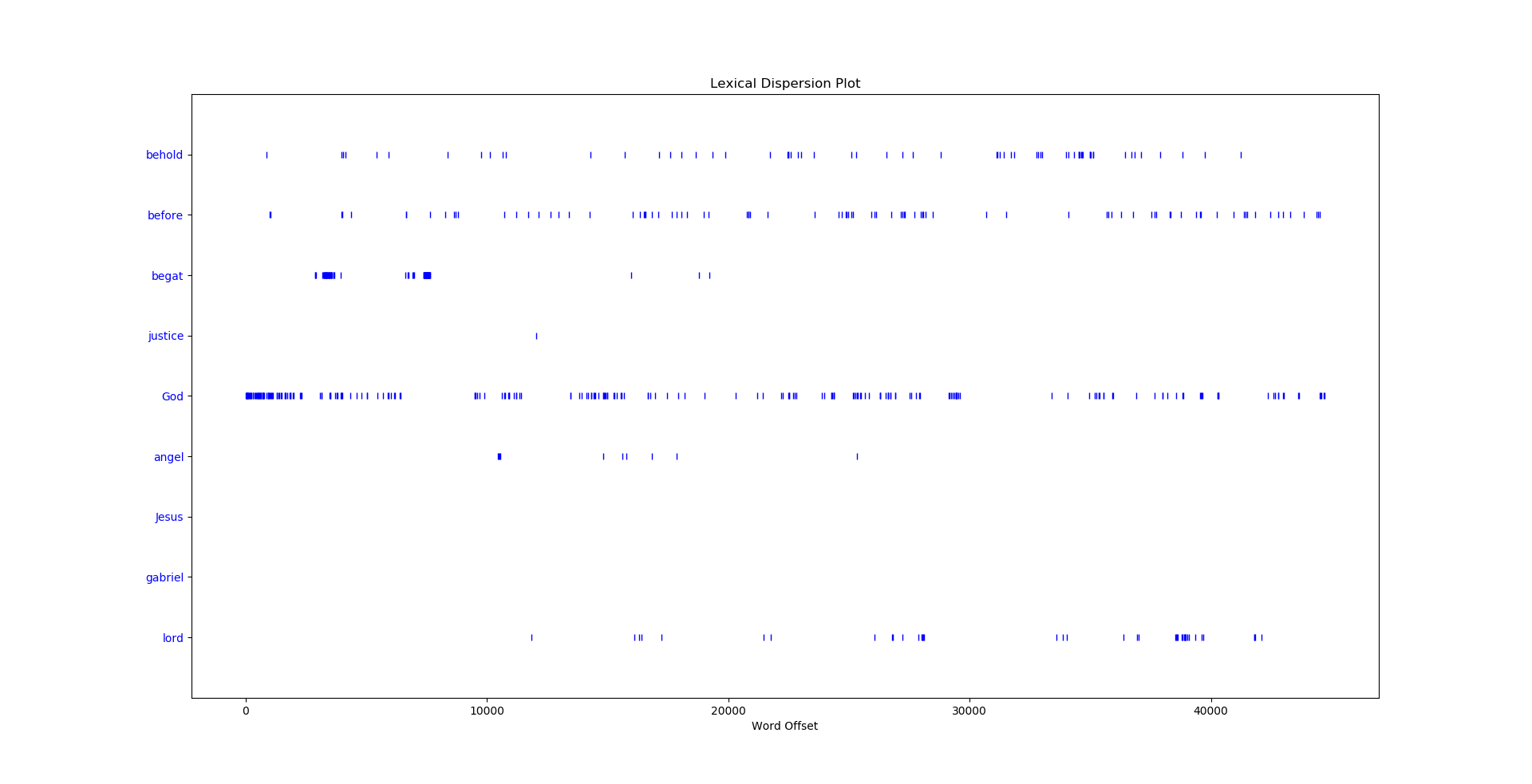
Dependent on the text and especially capitalization we can get wildly different results.
>>> text6.dispersion_plot(["Grail","wound","Camelot","Knights","King","Lancelot","Robin","Arthur"])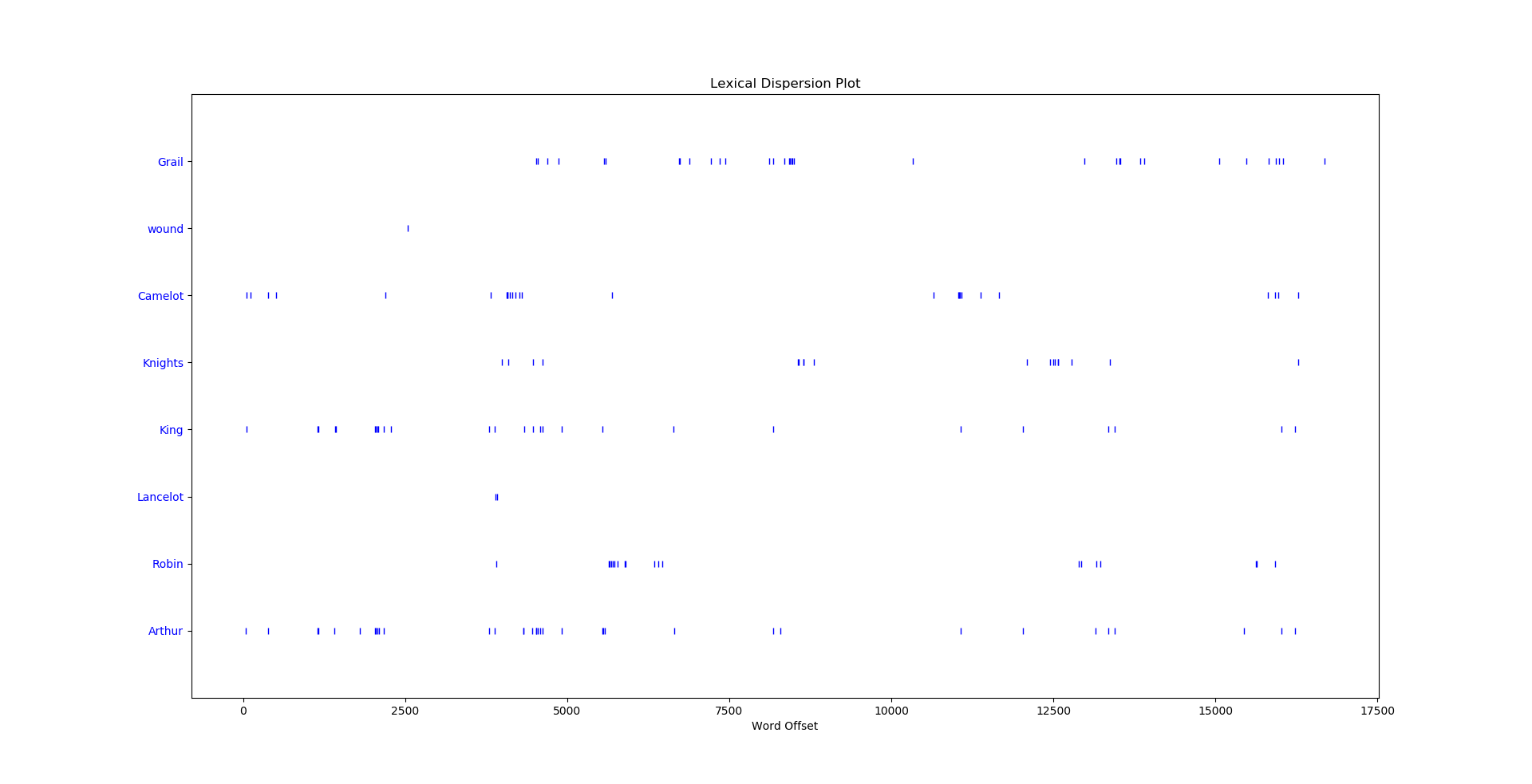
Counting Vocabulary
We can also count the vocabulary in our text as well.
Here we can see how many words there are in Moby Dick and other texts. It seems the more serious the book the more words that are included.
>>> len(text1)
260819Month Python is not as verbose.
>>> len(text6)
16967We can also count the occurence of specified words as well.
>>> text1.count("whale")
906If we want to find the percentage the word appears in our text we can utilzie the following code.
>>> 100 * text1.count('whale')/len(text1)
0.3473673313677301The word whale shows up in Moby Dick 34.7% of the time, which is not that surprising. So, lets try another one.
>>> 100 * text6.count('King')/len(text6)
0.1591324335474745
>>> 100 * text6.count('Grail')/len(text6)
0.20038899039311606Here we see the percentage the word Grail and King appear in Monty Python and the Holy Grail. Remember that capitalization matters, because we get a much different result with the following.
>>> 100 * text6.count('grail')/len(text6)
0.029468969175458243Frequency Distribution:
Next we can look at the frequency distribution (number of times a word appears in a text). We can get a running tally of how many times a word appears and plot it like below.
>>> fdist6 = FreqDist(text6)
>>> fdist6.plot(50,cumulative=True)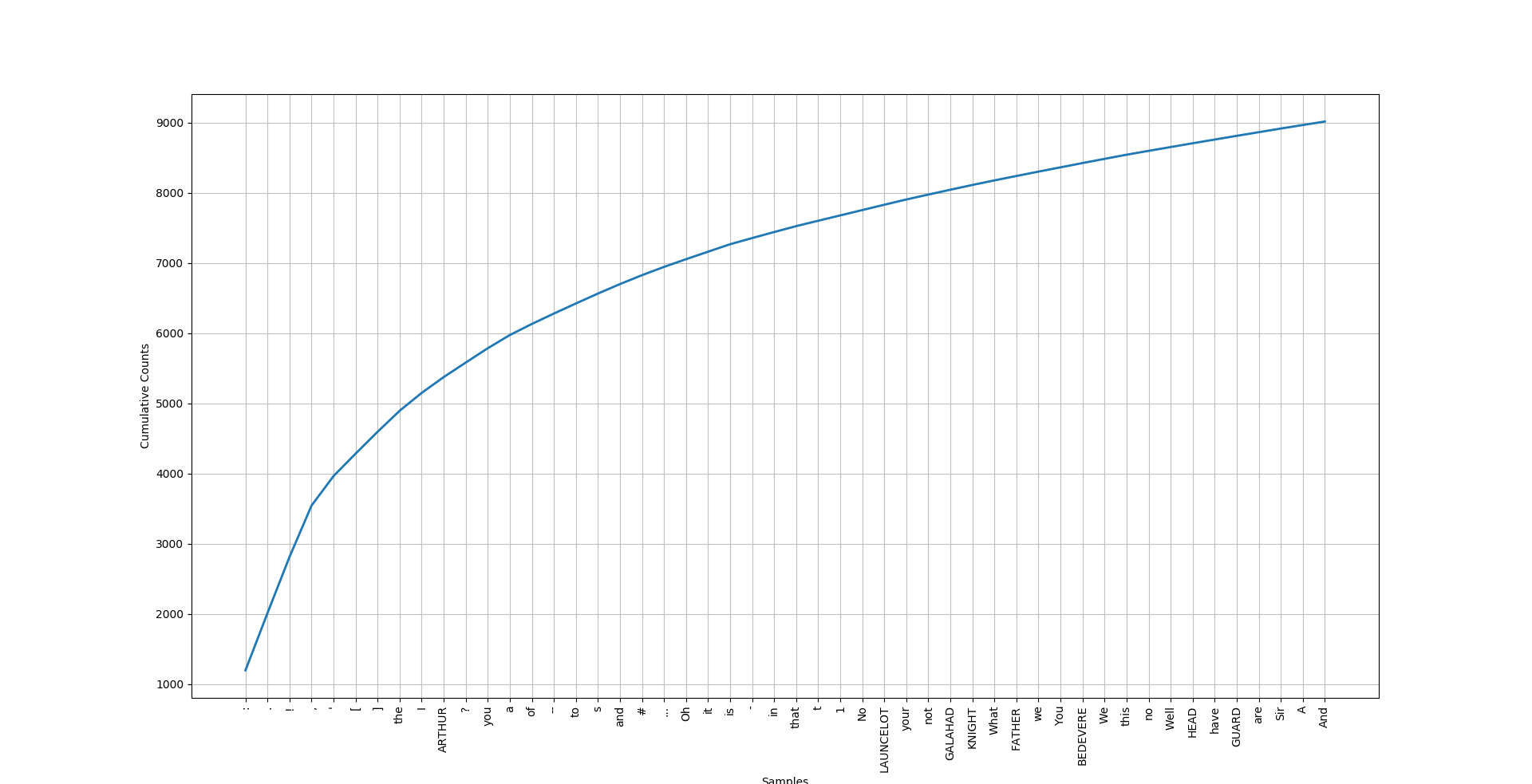
Find words of a certain length
Now lets find words of a certain length. We could manually type all of this out, but instead lets create a function to do this. Here our arguments are text and length and this allows us to specify different texts and lengths more interchangeably.
>>> def word_length(text,length):
V = set(text)
long_words = [w for w in V if len(w) > length]
return(long_words)Using our function we get the following: Notice we have wrapped our function inside the sorted() function in Python.
>>> sorted(word_length(text6,10))
['Auuuuuuuugh', 'BRIDGEKEEPER', 'Camaaaaaargue', 'Dramatically', 'Oooohoohohooo', 'Shrubberies', 'Unfortunately', 'accompanied', 'accomplished', 'approacheth', 'approaching', 'automatically', 'auuuuuuuugh', 'bridgekeeper', 'conclusions', 'considerable', 'dictatorship', 'differences', 'disheartened', 'distributing', 'earthquakes', 'elderberries', 'hospitality', 'illegitimate', 'illustrious', 'immediately', 'imperialist', 'impersonate', 'indefatigable', 'individually', 'influential', 'intermission', 'nnnnniggets', 'particularly', 'performance', 'perpetuates', 'perpetuating', 'regulations', 'shrubberies', 'suspenseful', 'syndicalism', 'syndicalist', 'understanding', 'varletesses', 'voluntarily']We can also look for words that are an exact length.
>>> def exact_word_length(text,length):
V = set(text)
long_words = [w for w in V if len(w) == length]
return(long_words)>>> exact_word_length(text6,10)
['Providence', 'horrendous', 'vouchsafed', 'repressing', 'remembered', 'personally', 'outrageous', 'Aaaaaaaaah', 'temptation', 'particular', 'chickening', 'conclusion', 'invincible', 'depressing', 'completely', 'unsingable', 'preserving', 'imprisoned', 'signifying', 'whispering', 'orangutans', 'undressing', 'government', 'Caerbannog', 'impeccable', 'shimmering', 'discovered', 'collective', 'successful', 'punishment', 'Everything', 'autonomous', 'Aauuggghhh', 'pestilence', 'everything', 'travellers', 'exploiting', 'understand', 'CHARACTERS', 'throughout', 'eisrequiem', 'absolutely', 'suggesting', 'interested', 'formidable', 'reasonable']The ever popular WordCloud
Utilizing the following code we can create the ever popular WordCloud. You will need the matplotlib, wordcloud, and os libraries installed.
>>> from os import path
>>> from wordcloud import WordCloud
>>> import matplotlib.pyplot as plt
>>> dirname = path.dirname(__file__path__)
>>> wordcloud = WordCloud().generate(text)
>>> text = open(path.join(dirname, 'romeo.txt')).read()
>>> wordcloud = WordCloud().generate(text)
>>> plt.imshow(wordcloud, interpolation='bilinear')
>>> plt.axis("off")
(-0.5, 399.5, 199.5, -0.5)
>>> plt.show() You should see a result like the one below. You will need to simply save any text you want to create a WordCloud for in a .txt file. I have used my own romeo.txt file above which obviously utilizes the play Romeo & Juliet.
